Did you know that deep learning was actually introduced back in 1943, yet only gained significant traction with the growth of computers and powerful GPUs? That’s right! How to learn deep learning has transformed from an obscure academic pursuit into one of today’s most valuable career skills.
Deep learning, a branch of AI that mimics how the human brain processes information, now powers everything from speech recognition to self-driving cars. However, getting started might seem overwhelming when you consider the prerequisites: statistics, linear algebra, calculus, and Python programming. Furthermore, the field evolves rapidly, with frameworks like TensorFlow, PyTorch, and Keras constantly updating.
The good news? With a structured deep learning roadmap, you can build proficiency in just a few months if you’re already comfortable with machine learning basics. For those starting from scratch, learning deep learning requires a bit more patience, but the career rewards are substantial.
From building your foundation to creating practical projects, we’ve mapped out the most efficient path to help you master this transformative technology.
Table of Contents
Build Your Foundation First

Anyone wondering how to learn deep learning must establish a solid foundation before rushing into neural networks and backpropagation. Essentially, your journey begins with mastering the right programming language. Python is the top choice for deep learning; it is simple, versatile, and rich in libraries (e.g., TensorFlow, PyTorch). Avoid jumping into other languages like C++, R, or Java until Python fundamentals are strong.
Beyond programming, mathematical knowledge forms the backbone of understanding deep learning algorithms. Here is what you need to focus:
- Linear algebra allows you to understand how neural networks transform data using vectors and matrices.
- Calculus helps you grasp gradient descent algorithms that power model training.
- Probability and Statistics enable you to analyse datasets and evaluate model performance properly.
Many aspiring practitioners become frustrated when diving into a deep learning course without these prerequisites. You cannot:
- Master mathematical foundations and programming basics
- Learn ML basics before jumping into complex deep learning architectures
- Understand why different models work for different problems
Such courses can help you build your foundation, which can help you effectively presenting your ideas and implement them in the project.
Master Core Deep Learning Concepts
Once you’ve built your foundation, understanding the neural network architecture becomes the next crucial step in how to learn deep learning. Neural networks, the fundamental building blocks of deep learning, simulate how the human brain processes information through interconnected neurons.
Artificial Neural Networks (ANNs) give machines the ability to accomplish human-like performance for specific tasks. What makes a neural network “deep” is simply the presence of multiple hidden layers between the input and output. These additional layers allow the network to learn increasingly complex features from the data, hence the term “deep learning.”
The activation function plays a vital role as the decision-maker within each neuron. It determines whether information should pass to the next layer based on its significance. Without activation functions like ReLU, Sigmoid, or Tanh, a neural network would merely be a linear regression model. Indeed, these functions introduce the non-linearity that enables networks to learn complex patterns.
When training begins, the network’s weights are randomly assigned, often resulting in incorrect predictions. This is where two crucial algorithms come into play: backpropagation and gradient descent. Backpropagation calculates the gradient of the loss function by propagating errors backwards through the network. Subsequently, gradient descent uses these gradients to adjust the weights, minimizing the cost function towards optimal accuracy.
The learning process follows a structured pattern:
- Data enters the network (forward propagation)
- The network calculates loss (difference between actual and predicted outputs)
- Backpropagation computes gradients
- Weights update based on these gradients
Get Hands-On with Tools and Projects
Theory alone won’t make you proficient in deep learning, practical experience is where true mastery happens. After grasping the core concepts, your next step on the deep learning roadmap involves getting your hands dirty with frameworks and projects.
Popular deep learning frameworks serve as your essential toolkit. Primarily, you’ll want to focus on:
- TensorFlow: Developed by Google, offering strong visualisation through TensorBoard
- PyTorch: Favoured in academia and research for its intuitive design
- Keras: Built for rapid experimentation with a user-friendly API
- MXNet: Excellent for distributed computing across multiple GPUs
Each framework has unique strengths, yet most quality deep learning online course focuses on either PyTorch or TensorFlow with Keras. While exploring these tools, remember that your goal isn’t to master every framework but to become proficient with one that suits your learning style.
Projects serve as the bridge between theory and application when learning deep learning from scratch. Beginners should start with structured, well-documented projects like:
Image classification using MNIST dataset Text summarization with sequence-to-sequence models Real-time object detection with YOLO Music genre classification from audio data
These projects allow you to apply theoretical knowledge to practical problems. Ultimately, completing projects enhances your understanding far better than passive learning alone. As you progress, gradually increase project complexity, moving from simple classification tasks to more sophisticated implementations like neural style transfer or image captioning.
Throughout your journey, balance between following tutorials and experimenting independently. Although following a structured deep learning course provides direction, personal experimentation fosters deeper understanding. In addition to frameworks, familiarise yourself with tools like Jupyter notebooks for prototyping and GitHub for version control.
The path to mastery requires consistent practice, dedicate time to coding regularly, join communities to share your work, and don’t shy away from examining others’ code.
Conclusion
Mastering deep learning takes dedication, patience, and a structured approach. As this roadmap shows, a solid foundation in Python, math, and ML basics is essential before diving into neural networks. Grasping concepts like backpropagation and network architecture shifts you from using pre-built models to building your own. Tools and frameworks support turning ideas into real applications.
But theory alone isn’t enough: projects are critical. They connect your learning to real-world solutions, making any course more impactful. Stick to a simple method: master the basics, understand the theory, and apply through projects. This holds true no matter which course or tool you choose. Lastly, engage with the community. Forums, open-source contributions, and competitions accelerate growth far beyond solo study.
Wait! Before You Go, Read:
 Fun and Learning: The Connection for Serious Students
Fun and Learning: The Connection for Serious Students
 Instapaper vs. Pocket: A Deep Dive into Read-It-Later Services
Instapaper vs. Pocket: A Deep Dive into Read-It-Later Services
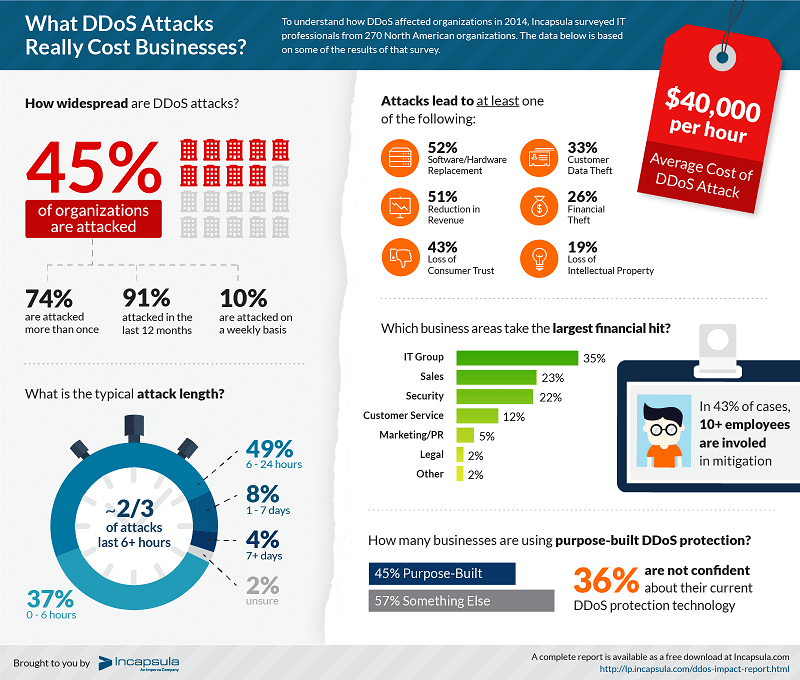 Learn About DDoS Attacks and How to Protect Your Online Business
Learn About DDoS Attacks and How to Protect Your Online Business
 Machine Learning and AI in Application Security
Machine Learning and AI in Application Security
 Machine Learning Algorithms in FOREX Trading
Machine Learning Algorithms in FOREX Trading
 The Beginner’s Guide to Navigating Stock Trading Platforms
The Beginner’s Guide to Navigating Stock Trading Platforms
 Beginner Tips to Invest in Futures Trading
Beginner Tips to Invest in Futures Trading
 Make Your First $100 Online: A Beginner’s Business Toolkit
Make Your First $100 Online: A Beginner’s Business Toolkit
 Navigating the Future of Investments: A Deep Dive into Real Estate Crowdfunding
Navigating the Future of Investments: A Deep Dive into Real Estate Crowdfunding
 Beginner’s Guide to Making Your First Commission with CPA Offers
Beginner’s Guide to Making Your First Commission with CPA Offers
 Fearing Chapter 7? Here’s What You Need to Learn
Fearing Chapter 7? Here’s What You Need to Learn
 How to Create Corporate Learning Programs That Align with Business Goals
How to Create Corporate Learning Programs That Align with Business Goals
 Twitter Analytics: Understand Data and Learn to Use It
Twitter Analytics: Understand Data and Learn to Use It
 Creating Viral Content? Learn The Secret Here!
Creating Viral Content? Learn The Secret Here!
 How To Reply To Comments In A Clear And SEO Friendly Manner On My Blog?
How To Reply To Comments In A Clear And SEO Friendly Manner On My Blog?
 A Beginner’s Guide to Filing a Personal Injury Claim After a DUI Accident
A Beginner’s Guide to Filing a Personal Injury Claim After a DUI Accident
 How to Make Your Blog Search Engine Friendly
How to Make Your Blog Search Engine Friendly
 You’re Probably Overlooking These 5 Business-Friendly Social Media and Directory Sites
You’re Probably Overlooking These 5 Business-Friendly Social Media and Directory Sites
 Best Health Insurance Plans in India for 2025
Best Health Insurance Plans in India for 2025
 98 Before & After Caption Ideas for Instagram (2025 List)
98 Before & After Caption Ideas for Instagram (2025 List)
 Online Loan Sri Lanka: 2025 Guide to Fast, Secure Borrowing
Online Loan Sri Lanka: 2025 Guide to Fast, Secure Borrowing
 Nueva Wealth Reviews 2025: How Are Traders Making It Work?
Nueva Wealth Reviews 2025: How Are Traders Making It Work?
 What To Know About a Web Development Company in New York
What To Know About a Web Development Company in New York
 Behind the Scenes of AI Tools: What Powers Them and Why It Matters
Behind the Scenes of AI Tools: What Powers Them and Why It Matters
 The Best Trading Brokers In 2025: Trends And Predictions
The Best Trading Brokers In 2025: Trends And Predictions